Notes on contrastive learning
Let’s think about contrastive learning in the context of learning image embeddings. The goal is for similar images to be closer together in the embedding space, and more dissimilar images to be further apart.
To make sure the embedder makes use of all the dimensionality of the embedding space and to prevent degenerate solutions like mapping everything to the same point, we push random pairs of images away from each other. We now have a spread out cloud of points, but their positions aren’t meaningful; this may as well be a hash function.
Consider taking some image, and creating a slightly rotated copy. It’s clear that this image should ideally embed very closely to the original, but as things stand it may end up very far away. We can solve this specific problem by pulling images and their augmented versions closer together.
These two operations are actually all there is to contrastive learning. But so far, this sounds to me like a glorified perceptual hash. Why does pulling images and their augmented versions together produce global structure?
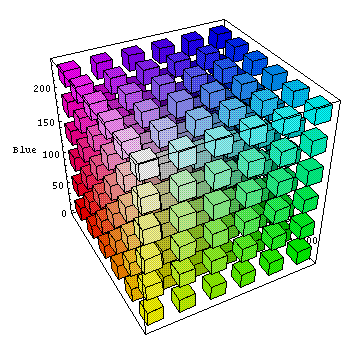
Let’s think about what the whole process might look like for single RGB values. We can represent the pulling of each color closer to slight variations of itself (neighbors on this color cube) as drawing an edge between two vertices in a graph. In this example, it’s clear that the shortest path distance between two colors will be roughly proportional to their visual difference.
Likewise for images, we can say that more similar samples are fewer local augmentations away from each other than vastly different ones. Unlike in the RGB example, we’re not enumerating every possible image, so the idea of a fully connected discrete graph doesn’t exactly apply. With that said, when we have many images, especially relative to our number of embedding dimensions, the augmentation distributions of images may start to overlap and form chains analogous to the prior example.
Also: such embeddings are commonly used for the task of semantic similarity, but nothing we’ve done thus far seems to strongly support the “semantic” part. It turns out that this isn’t something inherent to the contrastive learning algorithm. This makes sense; it feels unlikely that such a complex and subjective metric would spontaneously emerge.
The model’s notion of similarity is prescribed by the set of augmentations used during training. If we trained it with “change the color of n pixels”, we might get a embedder that approximates hamming distance. A model that can do semantic similarity is the result of a carefully chosen set of augmentations that destroys as much of the visual match as possible while still depicting “the same thing”.