Reflection on CMIMC Programming
This past weekend, I competed in CMIMC Programming 2026. It's a programming contest hosted by a club at Carnegie Mellon University. You can read more about it here.
Our team, Magnolia, took 1st place among the combined HS + undergraduate contestant pool.
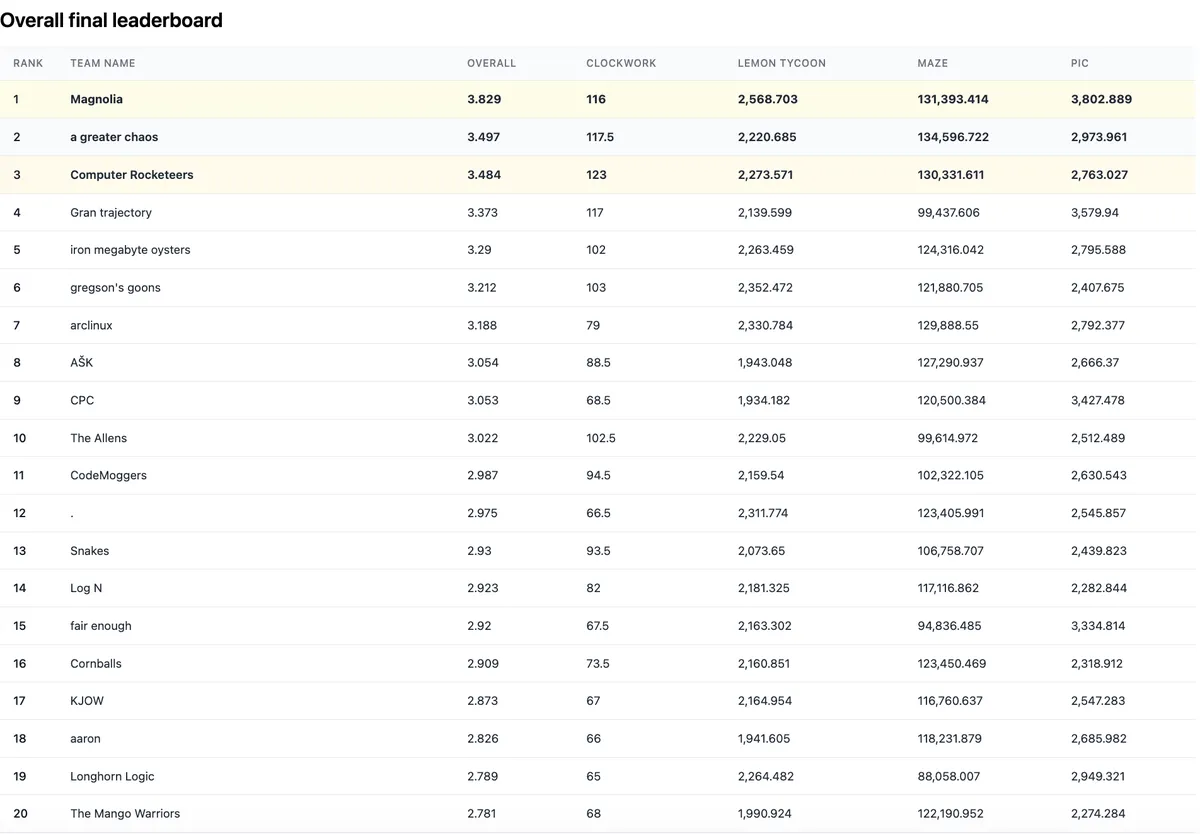
This was my 3rd and final year participating, placing 2nd in 2024, then 1st in both 2025 and 2026. I've been reflecting on how much LLMs have changed things across those 3 years.
Back in 2024, the most advanced model available is GPT-4. It genuinely feels like a lifetime ago. I nervously read up on simulated annealing and other optimization algorithms the day before the contest in a last minute scramble, and cobble together a quite frankly doomed idea on Friday night before submissions open.1 My ability to rapidly implement and iterate from competitive programming is my greatest asset, and every gain on the leaderboard feels tangible and satisfying.
It isn't quite true that AI has no part in my performance, though. That year, the contest spills past the weekend and into the whole following week. I use ChatGPT to help me get through schoolwork as I grind the Don't Connect 5 problem non-stop, including during all my classes. Good times.
AI helps clear space for me to compete.
Fast forward to 2025, and I'm running o4-mini, still in the chat interface. Notably, I start to write almost all my code using AI; but the models still don't feel smart enough to provide meaningful ideas, and without reliable agentic abilities I'm still doing a lot of hands-on work.
For Color War, I simplify the problem to a Voronoi game and come up with a playing strategy and algorithm. I get ChatGPT to write it, with optimized NumPy operations for faster move evaluation. Implementation is a manual loop: I run benchmarks, paste the timings back into the chat, point at bottlenecks, try the next optimization, and repeat. It's a big departure from the year prior, but I'd still say I'm solving most of what's "meaningful".
AI does the grunt work so I can do the actual thinking.
This year, in 2026, I'm running Opus 4.7 in Claude Code. Throughout the duration of the contest, I don't manually intervene in the codebase at all. All coding, debugging, benchmarking, testing, and experimentation is done through the agent. Having outsourced virtually all of the technical work, my contribution consists of directing the research direction and offering a handful of impactful abstract ideas.
For Pic, most of my contribution boils down to maybe 2 hours or so of actual thinking. From the visualizer, it seems like there's enough information from the incomplete image to reconstruct it with reasonable accuracy. Maybe that's useful? After some discussion and reasoning through the game theory with a teammate, we conclude that it's only slightly suboptimal at worst, or genuinely beneficial at best, to have our bot not cooperate with other teams at all.
So I binary search for the max file size by submitting junk to the judge, tell Claude to start training a CNN denoiser ~1024 kB in size... and just turn off my brain for the rest of the contest. Each detail of the model architecture, training regime, processing pipeline, and everything else constituting our final submission is done completely hands-off by AI in an hours-long research loop.

As my submission pulls away at a far 1st place on the leaderboard, I feel uneasy. How much of that standing is thanks to some increasingly nebulous skill, and how much is due to my honestly quite high token spend on a frontier model? I'm not sure.
For Lemon Tycoon, it's so much worse. We start out on the straight and narrow, spending hours whiteboarding strategies, reasoning about the shape of the equilibrium, if there is one, and developing something like a theory of the game: a set of meta-invariant principles that should hold up no matter who we're playing. Naturally, we use Claude Code to implement our bot ideas, an arena with Glicko-2, etc.
At some point during Saturday evening, we start using AI to cross-breed strategies in an AlphaEvolve-esque way. The outputs quickly devolve into hundreds of lines of baroque slop... but they're topping our evals. I try to stay on top of what they're doing, but soon give up. We just let it run, grab a few diverse solutions among the top, and just submit them all to see how they do in the meta.
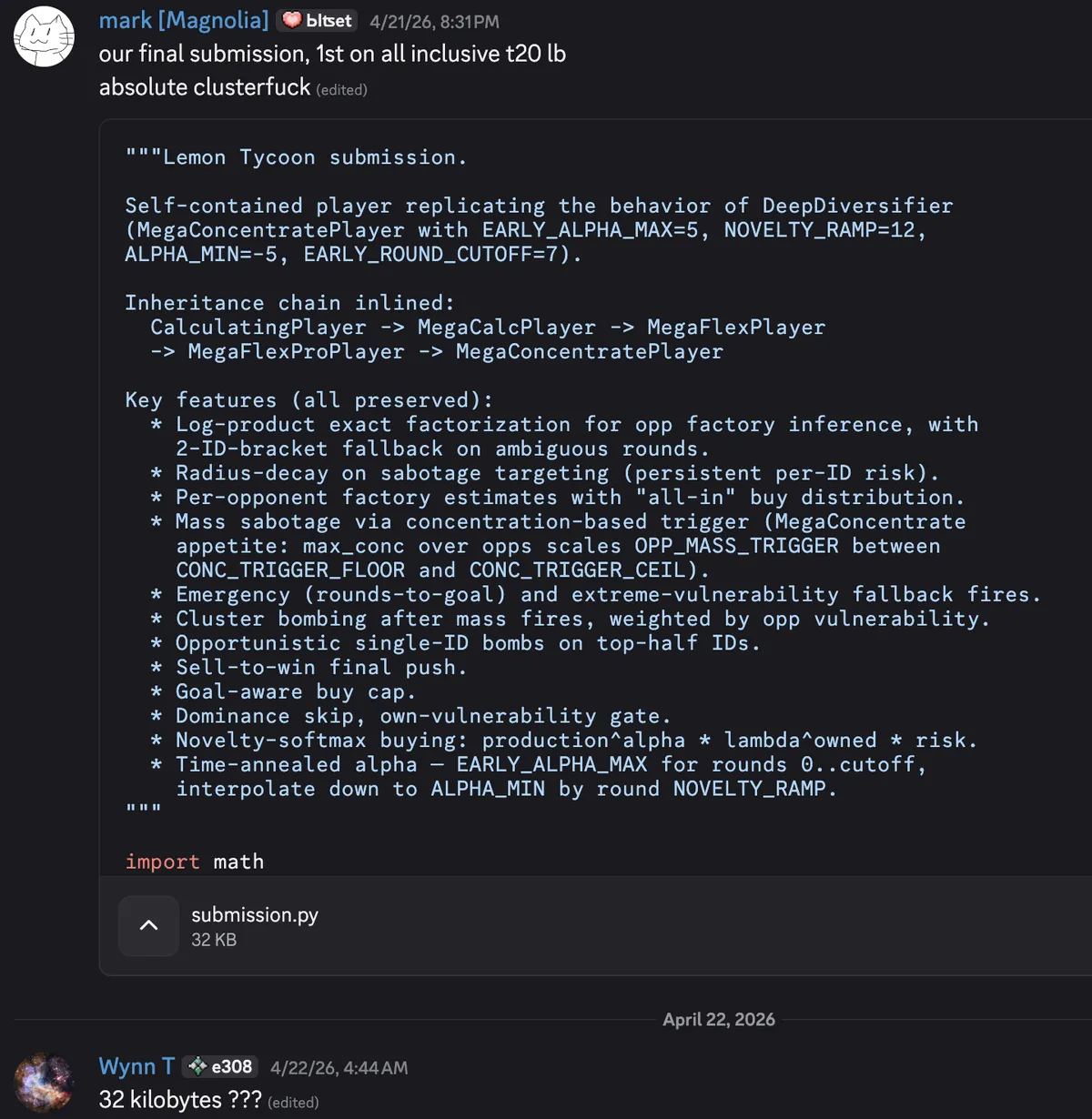
My post-hoc reasoning for this strategy is that we evolved a Pareto frontier of solutions of sorts. Also, maybe our seed of genuine ideas and thinking from the beginning enabled us to achieve good results from this process later on? Honestly, though, no matter how you slice it, it just doesn't feel right to end up in 1st with a submission none of us even understand.
We’re on top, so I must be contributing something meaningful, right?
Thank you to the CMIMC organizers. The problems were creative, the contest ran smoothly, and the whole thing is clearly a labor of love. These 3 years have been a lot of fun.
Not really important to the narrative, just some nostalgia for being new.↩